cargo-crap: Finding Untested Complexity in AI-Generated Rust Code

Rust makes many bugs impossible.
Memory safety. Thread safety. Ownership. Lifetimes. Exhaustive matching. Strong types.
But Rust cannot answer one essential maintenance question: Is this code safe to change?
A function can compile perfectly and still be risky to touch.
It can have too many branches, too many special cases, too many hidden paths, and not enough tests to give you confidence.
This is why I built cargo-crap is a Rust tool that finds functions that are both complex and poorly tested by calculating the Change Risk Anti-Patterns (CRAP) metric.
Coverage shows which parts of the code were exercised by tests. Complexity shows how many paths may exist through a function. CRAP combines both signals to highlight code that is risky to change.
I built it as one small guardrail for AI-assisted Rust development: agents can move fast, but we still need measurable checks around the complexity they introduce.
The problem with coverage alone
Code coverage is useful, but it can be misleading.
A small helper function with 0% coverage is not great, but it is probably not the biggest risk in your system:
fn is_empty(value: &str) -> bool {
value.trim().is_empty()
}Now compare that with a large function that parses input, validates business rules, handles multiple edge cases, mutates state, and has several nested branches.
If that function has 0% coverage, the risk is completely different.
Coverage alone does not tell you that. It only tells you what was executed during tests. It does not tell you how hard the code is to understand or how many paths exist through it.
The problem with complexity alone
Cyclomatic complexity measures the number of independent paths through a function. Every if, match, loop, and branch adds more possible paths.
That is useful information, but complexity alone is also not enough.
Some code is naturally complex. Parsers, state machines, protocol handlers, validation logic, and compatibility layers often branch because the domain itself branches.
If that code is well tested, the risk is lower.
The real problem is untested complexity, not complexity itself.
The CRAP metric
The CRAP metric was introduced by Alberto Savoia and Bob Evans in 2007 with crap4j, and Savoia later described the idea in more detail on the Google Testing Blog. It combines cyclomatic complexity and test coverage into a single number:
CRAP(m) = comp(m)² × (1 − cov(m)/100)³ + comp(m)Where:
comp(m)is the cyclomatic complexity of a functioncov(m)is the test coverage percentage for that function
You do not need to memorize the formula. The intuition is simple:
- Simple and well-tested code gets a low score
- Complex but well-tested code gets a moderate score
- Simple but untested code is not ideal but usually manageable
- Complex and untested code receives a much higher score
That last category is what matters because that is where code changes become dangerous.
There are two direct ways to improve a high CRAP score: reduce the function’s complexity or add meaningful tests around the important paths. The number is not meant to shame a function. It shows where refactoring or test work will reduce the most risk.
Why this matters even more with AI agents
AI agents are becoming part of everyday software development. They can generate code, refactor functions, add tests, update APIs, and move very quickly through a codebase.
That speed cuts both ways. It can also make code more complex or less tested than before.
With each automatically generated branch, exception, or fallback, an AI agent can gradually make a function harder to understand and test.
One pattern I see often is preservation by accumulation: instead of simplifying the model, an agent adds another fallback, another special case, or another compatibility branch to keep the current behavior working. The tests may still pass, but the function has become harder to reason about. The code compiles, yet the system has become harder to change safely.
cargo-crap serves as a boundary for AI-assisted development, alerting you when the score crosses your chosen threshold.
You can change code, but
cargo-crapmakes silent increases in high-risk, untested complexity visible.
That boundary matters even more when code is changed not only by humans but also by AI agents.
My intended workflow is simple:
- Let an agent implement the change.
- Run tests and coverage.
- Run
cargo-crap. - If the score increased, ask the agent to either simplify the function or add meaningful branch coverage.
What cargo-crap does
cargo-crap brings this metric into the Rust ecosystem as a Cargo-style tool.
If you use cargo-binstall, you can install a pre-built binary:
cargo binstall cargo-crapOr from source:
cargo install cargo-crapThe basic workflow is two commands:
cargo llvm-cov --lcov --output-path lcov.info
cargo crap --lcov lcov.info- First, you generate an
LCOVcoverage report. - Then
cargo-crapanalyzes your Rust source code, computes complexity per function, joins that with coverage data, and prints a ranked report:
┌───┬───────┬────┬───────────────────┬──────────┬───────────────┐
│ │ CRAP │ CC │ Coverage │ Function │ Location │
╞═══╪═══════╪════╪═══════════════════╪══════════╪═══════════════╡
│ ✗ │ 156.0 │ 12 │ ░░░░░░░░░░ 0.0% │ crappy │ src/lib.rs:24 │
│ ▲ │ 6.7 │ 4 │ ████░░░░░░ 44.4% │ moderate │ src/lib.rs:12 │
│ ✓ │ 1.0 │ 1 │ ██████████ 100.0% │ trivial │ src/lib.rs:8 │
└───┴───────┴────┴───────────────────┴──────────┴───────────────┘
✗ 1/3 function(s) exceed CRAP threshold 30.Instead of scanning large coverage reports and guessing, cargo-crap gives you a focused, ranked list of functions that need attention.
The default threshold is 30, which follows the original CRAP guidance: once a function crosses that line,
it is worth treating as a high-risk change target rather than ordinary background noise.
A small example
Imagine three functions:
| Function | Complexity | Coverage | CRAP |
|---|---|---|---|
| trivial | 1 | 100% | 1.0 |
| moderate | 4 | 50% | 6.0 |
| risky | 12 | 0% | 156.0 |
The first function is straightforward and fully tested. There is little to worry about.
The second has some branching and partial coverage. It might be worth improving, but it is not screaming for attention.
The third is the interesting one. A complexity of 12 indicates many paths through the code. With 0% coverage, every change becomes a small act of faith.
That is the function you probably want to look at before it surprises you in production.
Here is the kind of shape cargo-crap is meant to make visible:
fn classify_event(kind: &str, retry_count: u8, source: Option<&str>) -> &'static str {
if kind == "payment_failed" {
if retry_count > 3 {
return "manual_review";
}
if source == Some("partner") {
return "partner_retry";
}
return "retry";
}
if kind == "payment_succeeded" {
return "complete";
}
if kind == "refund_requested" && source != Some("internal") {
return "review_refund";
}
"unknown"
}This function is not huge, and Rust will happily compile it. But it already has several paths, early returns, and business rules hidden inside conditionals. If coverage misses most of those paths, the risk is not theoretical. The next person or agent that changes it has to guess which branches matter.
Here is an excerpt from PR #17,
which added SARIF 2.1.0 output to cargo-crap:
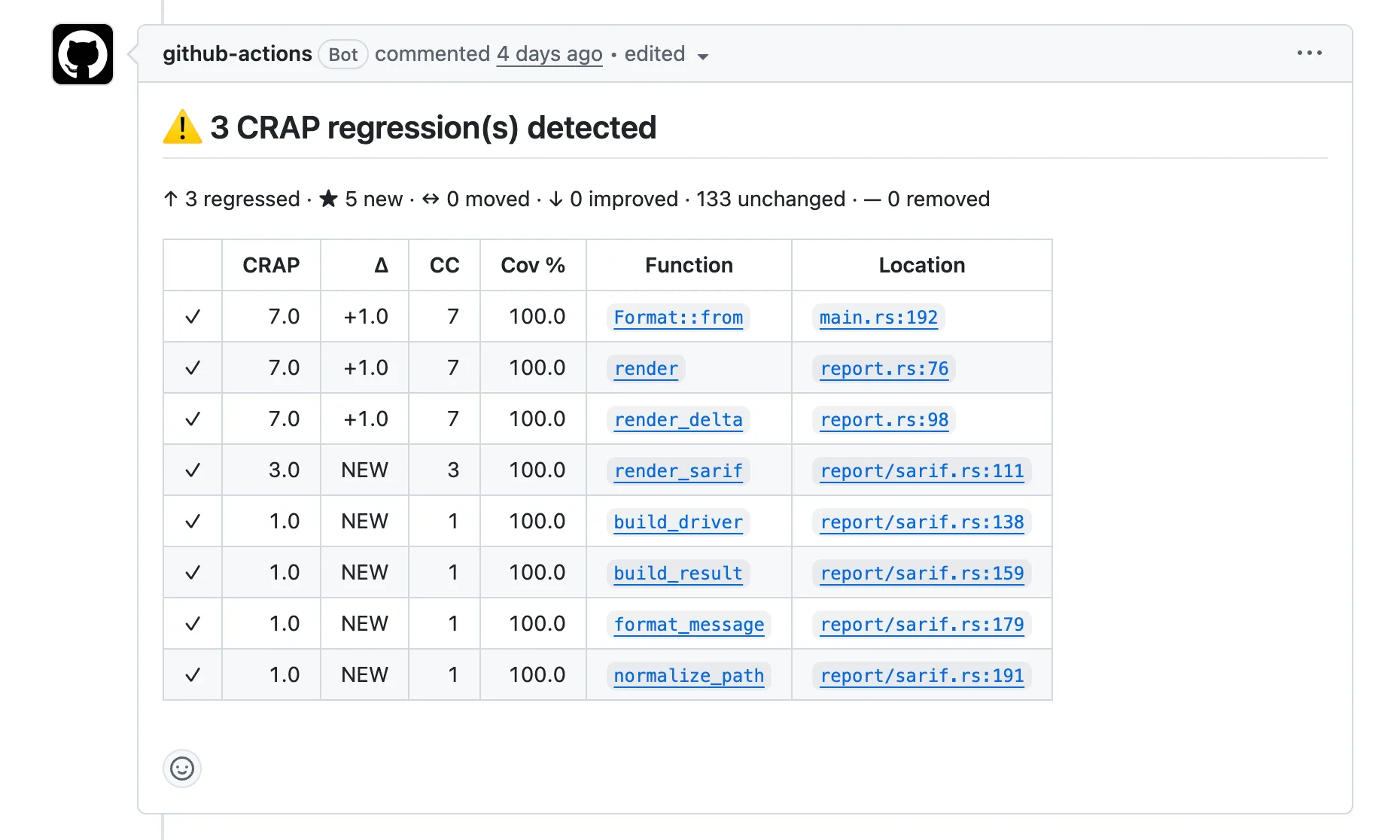
That comment changes the review conversation. Instead of asking “Does the PR look okay?”, you can ask more specific questions:
- Did the new output format add essential branching, or can the dispatch logic be simpler?
- Are the regressions acceptable because the affected functions are still fully covered?
- Should the threshold or baseline absorb this, or should the implementation be reshaped?
That is the practical value. It does not replace review, but it gives review a sharper starting point.
What this tool is not
- It is not a replacement for engineering judgment.
- It does not understand your business domain.
- It does not prove that your tests are good.
Coverage can execute a line without asserting the right behavior. A function can be fully covered and still poorly tested.
So the CRAP score should not be treated as absolute truth. It is a signal — a useful one.
The best use of the tool is to ask better questions:
- Why is this function so complex?
- Is this complexity essential or accidental?
- Do the tests cover the important branches?
- Can we split this into smaller pieces?
- Should this logic be modeled more explicitly?
Good tools do not replace thinking. They make thinking easier to focus.
This is most useful for teams with growing Rust codebases, large refactors, generated code, or AI-assisted pull requests. If your code changes quickly and review time is limited, a ranked list of risky functions gives reviewers a concrete starting point.
Using it in CI
You can use cargo-crap locally, but I think it becomes more useful in CI.
For new or small projects, an absolute threshold can work well. You can fail a build when a function crosses a threshold:
cargo crap --lcov lcov.info --fail-above --threshold 30For existing projects, I would be careful with strict thresholds. Most real codebases already have some legacy complexity. If you turn on a hard gate immediately, you may get a long list of old problems that nobody is ready to fix right now.
For mature codebases, I would start with baseline mode:
cargo crap --lcov lcov.info --format json --output baseline.json
cargo crap --lcov lcov.info --baseline baseline.json --fail-regressionThis does not pretend that the codebase is perfect today. It simply says:
We may have existing problems, but new changes should not make them worse.
That is a healthy engineering rule. It is especially useful for AI-assisted development, where you want fast iteration without losing control of the codebase.
You can also make the output reviewer-friendly. --format github emits GitHub Actions annotations,
and --format pr-comment produces a pull-request comment format that is easier to scan during review.
In GitHub Actions, the simplest threshold gate looks like this:
name: change-risk
on:
pull_request:
push:
branches: [main]
jobs:
cargo-crap:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: dtolnay/rust-toolchain@stable
- uses: taiki-e/install-action@cargo-llvm-cov
- run: cargo install cargo-crap
- run: cargo llvm-cov --lcov --output-path lcov.info
- run: cargo crap --lcov lcov.info --fail-above --threshold 30That is intentionally small. For a mature codebase, start with baseline mode rather than an absolute gate, then tighten the threshold later once the worst offenders are understood.
Final thoughts
Software quality is not only about whether the code compiles or whether tests exist. It is about whether we can safely change the system tomorrow.
That matters even more when AI agents can change code faster than humans can review every detail.
cargo-crap makes one problem visible: complex Rust code with insufficient test coverage.
The goal is not to make every number perfect or to ban change. The point is to make risky change visible before it quietly becomes normal.
Rust gives us strong guarantees about what our programs cannot do. AI gives us speed. cargo-crap helps connect those two realities with a simple rule:
Move fast, but measure the risk you are adding.